The technology behind Stadiaffinity

I would like that this post to serve as an ending to the project wich I worked on for a while. Even while the end of the Stadia (and Stadiaffinity, as a consecuence), made me feel truly sad I need to say that both projects were a good thing for me. I learned a lot while building Stadiaffinity and met some great people from the Stadia community.
A brief introduction to Stadiaffinity
The idea behind Stadiaffinity was to create a platform where people could discover games that they would like to play even if they don't know anything about the game, nothing about the genre, the mechanics or anything else. To achieve this, the platform would ask you to rate the games you played, and it would show you the games that you probably like to play using an affinity indicator.
The affinity algorithm was based on the following principles:
- Should not be guided through genre or any other taxonomy, e.g. if you liked a metroidvania, doesn't mean that the algorithm will recommend you one hundred of another metroidvanias because you probably already know these games.
- The final mission is to discover games, that means that should be able to recommend you games that you would never have been interested in, but that you would like to play.
These principles could be summarized in the following example: If you like Sekiro, there are many chances that you will like Celeste, even if they are basically opposite in graphics and nothing related in gameplay. Because there are something more relevant: the player feelings.
The stack used
The project was built using the following technologies and services:
- React through Next.js
- Tailwind CSS
- Supabase for the Postgres database, the authentication and the storage
- Vercel for the hosting
It's incredible how well the stack works together 🤯
What about Supabase?
Supabase is the game changer. Even while I've been using before it was turned General Available, it worked flawlessly. Supabase served as the core of the project: it dealed with the user authentication, the database and the storage. And all these magic reunited into an API. Let's talk about this.
It uses Postgres, and Postgres provides a powerful tool called functions. With these functions, you can create complex queries that could be parametrized, exposed and used by other applications, like the frontend.
On the other hand, Supabase also provides a well done set of utilities to work with specific frameworks, in this case Next.js. And using this utilities you can consume the API created with the Postgres functions. I'm not saying that this is always the way to go, but is incredible to see that you can create an entire project using this arquitecture.
A small example of a function
Imagine that you have a SQL query that returns a list of games that the user has bookmarked, similar to this:
SELECT
games.id,
games.name,
bookmarks.created_at
FROM bookmarks
INNER JOIN games ON games.id = bookmarks.id_game
WHERE id_user = id_user_inputHere, the id_user_input in the last line is a parameter that can be used to the function, and Supabase automatically creates even the documentation (more like an example) for this function, something like this:
let { data, error } = await supabase.rpc("get_user_bookmarks", {
id_user_input,
});
if (error) console.error(error);
else console.log(data);You can use the previous code into a a SSR page or RSC component and you don't need nothing else, 🪄.
The functions could be created using the Supabase UI (honestly a bit limited) or using SQL queries. Check the Postgres documentation for more information.
Back to Stadiaffinity, the algorithm
We've already seen what the algorithm should do and the tools to achieve it. Let's deep dive into the how to.
Regarding to the database tables... not to much to say here, imagine basically three tables, one for the users, one for the games and another one for the ratings that relates the previous two.
The algorithm is pretty simple. If you rate similar than another user, you probably like the games that the other user likes. And if the game rating average is high, it's obious that there is more chances that you will like it. Knowing this, we could use the similarity between users as a multiplier for the game rating. What means this? Again, better to explain with an example: Imagine a user called John. John liked The Division a lot. How relevant is this for you? Well, depending on how similar are your ratings with John.
Actually, even while the site exposes the affinity indicator on the games, it's looking for affinity between users (anonymously).
NOTE
Initially, I wrote a lot of SQL and described what they did, but I've decided to remove it from the post because it was too much, and I think that it's better to explain the idea with images and a simple example than with dozens of SQL lines.
I have a small formula to estimate the coincidence between users, It's pretty simple, something like this:
COINCIDENCE = SUM(5 - ABS(user1.rating - user2.rating))Example:
Game User 1 User 2 Coincidence
-------------------- --------- --------- ------------
The Division: 5 5 5
The Division 2: 3 5 2
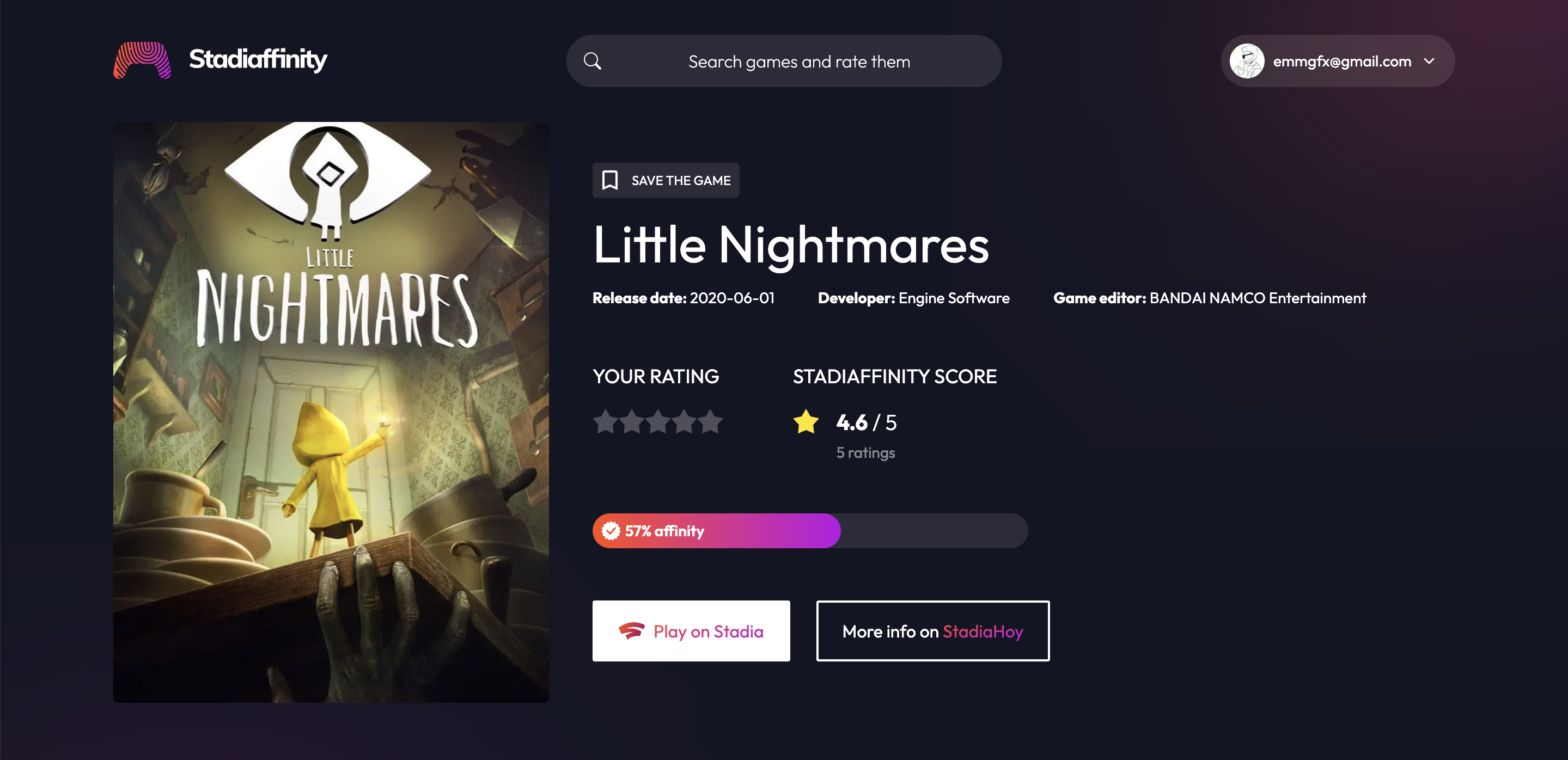
Little Nightmares: 5 2 3
Little Nightmares 2: 1 1 5
No Man's Sky: 0 5 0
# Total coincidence: 15But what do we do with this information? Look the following diagrams. The two diagrams starts with the same three games and the same average rating. The first one shows an scenario where the same three users rated the games, and the second one shows a parallel scenario where the other users doesn't rated the same games.
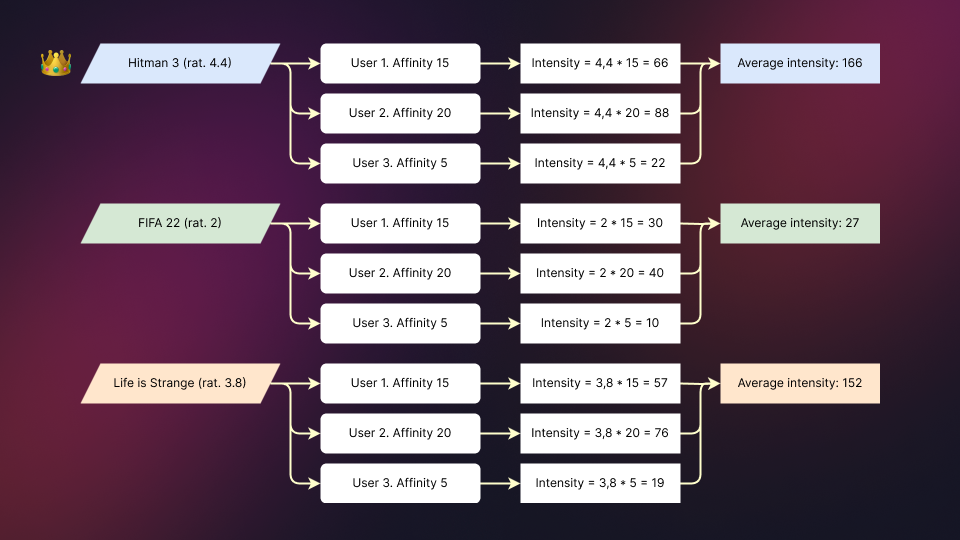

Noted how the algorithm works? Even if game rating is the same, you will have different recommendations (Hitman 3 on the first diagram and FIFA 22 on the second one) depending on your affinity with the other users.
But what about the performance?
Obviously the algorithm is not perfect. I've had some concerns about the performance in case of a large number of users because it manages a lot of information and it would increase exponentially... but remember the famous quote from Donald Knuth:
The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.
In the unlikely success of the service, I'd have time to improve, optimize and tighten some nuts. Meanwhile it worked nicely, to be honest.
About the UI/UX
The entire service, from the brand to the site UI and UX, was designed by Laura España. She did a great job and plasmed the idea that I had in my head, with invaluable contributions and improvements. It's always a pleasure to work with someone who knows how the things should be done and knows about the best practices and tools.
End of the story
And that was it. In this post I've exposed the tech stack, some of the reasons behind using Supabase and even a overall view to algorithm that powered Stadiaffinity. I hope that this post was useful for someone and maybe it will inspire to build something.